

Encoding variability and event segmentation across narrative contexts
Author’s Note
I was involved with Dr. Charan Ranganath’s Dynamic Memory Lab since shortly before the COVID-19 pandemic. I performed remote work since 2020 on multiple projects with the lab. I was very excited to begin working on my own project with the support of my mentor, James Antony, who has performed examinations on event segmentation in naturalistic contexts in the past. The psychology of learning and memory is particularly fascinating to me, and this exploratory project took shape because of the very simple desire to prove to myself as a student that I really was doing the right thing by studying the same concepts using multiple different methods. From there, it specified to a more “fun” sort of project—forcing my peers to watch a TV show. While my preliminary results generally pointed towards supporting my hypothesis, the true value of this project to me was simply in learning more about how to develop and run studies like this, with the hopes of improving in future.
Introduction
The encoding, processing, and retrieval of knowledge and environmental information is foundational to the operations of people’s everyday lives. The same information can be encoded in a variety of ways depending on the observer of this information and how context surrounding this information might change. This proposed understanding that memory improves when the same information is presented in multiple different contexts or encoded using different strategies, rather than with the same context or strategies, is called the encoding variability (EV) hypothesis (Huff, 2014). In narratives or naturalistic stimuli, recollection of information has additionally been shown to be affected by how people encode the occurrences they observe into discrete units–the segmentation of people’s everyday lives into events (Baldassano, 2017). The major focus of the present study was to examine the ways varying or maintaining modality in presentation of a narrative affected recall, and whether the segmentation of events across these modalities could be a factor in these differences.
Encoding variability
Memory is often dependent on the context of encoding. A student might recognize their teacher’s face in the classroom, but not at the supermarket, as their memory of this person is highly context-dependent on seeing them at school. The decontextualization of encoded information is key to its generalizability. Context is usually considered the environment of encoding, such as in the aforementioned example. In advocating the encoding variability hypothesis, Smith and Handy (2014) proposed that EV allows for decontextualization of the memory target, improving performance in later retrieval.
There is some controversy surrounding the EV hypothesis. Some studies have found an EV boost to memory; others have found no significant effect, or even a retrieval cost associated with varying encoding context in recollection (Huff, 2014; Young, 1982). However, these last studies often involved varying encoding tasks, rather than contexts (Huff, 2014). For example, Young and Belleza (1982) found that participants recalled target words better when employing a single strategy, or mnemonic device, for aiding recollection, rather than varying it. Varying mnemonics is not varying encoding context, it is varying the task. Additionally, memories of a piece of information may improve with contextual cues, though these tend to apply to less-studied or early memories of that information (Smith, 2014). Huff et al. (2014) additionally proposed that studies finding EV costs involved participants using the same type of processing across different tasks.
With these explanations, it is easier to isolate the benefits of EV. Huff et al. (2014) found EV benefits in a study which involved varying item-specific and relational processing between tasks. In their study, relational processing consisted of relating different items to each other, such as sorting them across various categories, and item-specific processing involved tasks like rating items individually. In this case, explicitly targeting encoding strategies rather than context worked well in showing EV benefits. EV benefits were also seen in often-used face-name pair recognition tasks. EV improves recollection of these pairs after they have been stored in long-term memory (Smith, 2014). In another study which varied the context (in this case, single words) before targets (celebrity names), EV benefits were again seen (Hintzman, 1978). Huff (2014) also found benefits in participant recall of weakly-related word lists. EV has previously been used to explain the spacing effect, which is the benefit to memory associated with items studied in a distributed fashion over a long period of time, rather than in a massed fashion (Glenberg, 1979). Distributed encoding of an item entails a variety of contexts, as opposed to the same context in massed studying. It is notable that many of these studies focus on simplistic stimuli, such as word lists or simple memorization procedures; these are not necessarily relevant to the everyday psychology of people.
Encoding knowledge with multiple strategies and contexts thus seems to be beneficial, at least for long-term memory. In everyday encoding of information, humans integrate information across many modalities at once–i.e. sight, olfaction, or audition. In humans integrating information across multiple modalities, early processing pathways of different modalities are distinct, but share structure in higher-order brain areas, such as in the prefrontal cortex (Jung, 2018; Handjaras, 2016). In one study, participants were given the task of listing properties that would belong to an audibly- or visually-presented stimulus; results indicated that the neural representation of knowledge, here features of some subject, are represented in a distributed manner, with modality-dependent information integrated locally and then used to build more abstract representations (Handjaras, 2016). These representations were similar across participants, whether sighted or visually impaired. Varying the modality of presentation of the same information might involve different small-scale processing changes in the brain, with larger-scale integrations of information being largely similar across humans. Varying encoding strategy by varying modality of presented information, especially in narratives, has not been well-examined.
Event segmentation
In daily life, humans confront a constant stream of information and break this down into discrete units. Event Segmentation Theory (EST) provides an explanation for the construction and continuous update of events during perception and recall (Zacks, 2007). Defining an event is tricky: events can last seconds, or hours; an event may involve animate actors with goals, or it may involve a natural phenomenon; it is often hard to say where one event ends or one begins. In narratives, where one event ends and another begins might be more obvious, with changes in perspective characters, settings, or subplots. EST proposes a number of properties about events, defined in most cases as the meaningful segments of one’s life or experience (Newtson, 1976; Baldassano, 2017). First, it offers that perceptual processing is hierarchical, with perceptual predictions occurring later in the hierarchy after the integration of sensory inputs and construction of event models; event segmentation is recurrent, so that late stages affect earlier ones; and event segmentation is cyclical, meaning that predictions are constantly compared to what actually happens (Zacks, 2007). Importantly, an event seems to be able to be temporally or spatially interrupted, but still integrated as a single narrative in the brain (Cohn-Sheehy, 2020).
Event segmentation is particularly relevant to a person recalling information from a narrative or their everyday lives. Some of this relevance stems from the improvement to memory granted at event boundaries, when one event ends and another begins. The key to updating event models at these boundaries are prediction errors, which are the distances between the mind’s calculation of an expected result and the observed value of that result (Zacks, 2007). In particular, violations in predictions have been shown to coincide with event boundaries, which can be visualized in the brain as shifts between stable patterns of activity (Antony, 2020; Baldassano, 2017). In naturalistic stimuli, like a basketball game, these violations in predictions are associated with surprise (Antony, 2020). Certain aspects of this segmentation have been shown to improve or impair recall. Memory seems to be improved at event boundaries, and there is some evidence that it is impaired immediately after (Zacks, 2007). Additionally, recollection of certain events may interfere with each other if they have some overlapping element (Cohn-Sheehy, 2020). In a study of event segmentation within a basketball game, for example, participants recalled few possessions of the ball, most likely because of interference between similar clip contents (Antony, 2020). Narratives, which provide strong, causal associations between events, may benefit retrieval compared to events that have not been integrated but share certain elements (Cohn-Sheehy, 2020). The hierarchical nature of event segmentation has been indicated with changes in event boundaries at different attended timescales, with finer-grained event boundaries detected at lower-order sensory areas in the brain and coarser-grained event boundaries detected at higher-order areas, coinciding with more abstract understanding of events (Antony, 2020). Information from different modalities may be segmented differently–multimodal integration that updates an event model of the current situation is a key step to abstracting information. This might be affected when information from different modalities is isolated.
Current study
In the present study I examine encoding variability in a narrative context, and discuss briefly the relationship of encoding variability with event segmentation. In the first portion, participants segmented events across an episode of a television show in either audio description or visual-only formats. With the actual narrative beats of the story remaining constant between versions, subtle variations in event segmentation are likely due to differences in processing the two formats, which is relevant to discussion of modality-dependent encoding variability. In the second portion, I applied repeat testing of these episode formats to two different groups: one group watched a section of the episode and rewatched it in the visual-only format (with captions) and the other group rewatched the episode in an audio description format, mixing the visual and auditory modalities. We expected that mixing modalities would produce a significant memory-boosting effect upon free recall.
Methods
Episode
This study was split into two distinct portions. For both portions, a particular episode from popular TV show Friends was used to collect the data. I chose an episode from season one of the show (Episode 9, “Blackout”) that used a variety of plots and characters to produce a number of events and narratives that could be tracked throughout the episode. This particular episode has two major plots: one with most of the characters in an apartment, and the other with the last of the titular friends (“Chandler”) stuck in a bank lobby. The visual portion used captions taken from HBO Max’s captioning of the show; the audio description of the episode was taken from HBO Max. Participants who had seen the show before were noted, but not excluded from the study. I created a “storyboard” of the episode based on scene transitions, timing, and character entries and exits from scenes to compare to both portions of the study.
Event Segmentation
For the event segmentation portion, 25 undergraduate students attending UC Davis were gathered using Sona, a system which provides course credit in exchange for research participation. Due to technical errors or dropout, obvious lack of engagement (lack of button presses), or in one case, constant button presses, certain participants were excluded. These exclusions left 8 participants in the audio-only group and 8 participants in the video-only group. They were sent emails with the link to the study. Participants were presented with a button, which they were to click when an event ended and a new one began. These instructions were as follows: “Click a button when one unit of the show ends and another begins. By clicking the button, you will mark off the show you’ll be seeing into the largest units that seem natural and meaningful to you.” This instruction was given in accordance with prior studies (Baldassano, 2017; Antony, 2020). Participants were randomly assigned to a visual-only or audio-only group and were notified that they should not be hearing any audio or should not be seeing a video, respectively. They watched the episode once and pressed the button in accordance with the directions above. The response times to button presses were collected in milliseconds, standardized to the start of the episode (different on each participant’s machine), and were aggregated for observation. Pearson correlation coefficients were calculated in Google Sheets and tested for significance.
The study was hosted using ngrok, an application that allows the hosting of a webpage on a local machine (ngrok). Serverside management was handled through JATOS (Jatos). JATOS cooperates well with jsPsych, which was used to provide the Javascript and HTML framework for the study (jsPsych). In particular, jsPsych’s video-button-response and audio-button-response plugins were used and modified as necessary to allow for recordings of multiple button presses.
Free Recall Portion
A separate group was recruited for the free recall portion of the study. These were 37 college-aged undergraduate psychology students attending UC Davis, again gathered using Sona. Two of these participants were excluded due to lack of engagement in the free recall post-viewing. They were split into two groups, with 18 participants randomly assigned to watching the same Friends episode twice in a visual-only format, 17 watching the Friends episode first, then listening to an audio description version of the episode. Five participants in the visual format had viewed Friends in its entirety before; eight participants in the mixed visual/audio group had viewed Friends in its entirety before. These sessions occurred over Zoom with screensharing to provide viewership of the visual or auditory format of the episode, always in groups of three or less to minimize lag. These participants were then sent a Google form where they were asked a number of questions, most notably asked to recount freely what they recalled happening in the episode.
Participants in both conditions of the study deviated widely in the amount of details provided. To collect these details, the transcripts were randomized, so it was unknown which condition they emerged from. Then, each detail was summed, sentence by sentence, and assigned to the episode storyboard. Different amounts of details were readily available from each scene, so while some scenes were often recalled at high levels of detail (9-11 details), other scenes would never be recalled beyond one or two details. Among what might intuitively qualify as a recalled detail, such as the appearance of an onscreen animal, the first mention of a location of a subplot, or paraphrasing of dialogue, participants’ recollection of main characters’ names was not qualified as a detail, as it placed too great a disadvantage on those who had not viewed the show before, although some tests excluded those who had previously viewed the show.
Detail summations were compared across conditions via a heteroscedastic two-sample t-test using Google Sheets T.Test function to determine the level of statistical significance against the null hypothesis.
Results
Event Segmentation
Between the audio and visual conditions, there were varying amounts of event boundaries and they were localized differently. These differences are visible in Figure 1 and Figure 2. The same event might be caught at slightly different times between versions. For example, 1025 seconds in, the auditory version involves the narrator transitioning from describing a character’s expression in one scene to another scene in the same sentence; the visual version displays a hard cut that is more noticeable and earlier. Event boundaries were detected to different extents. Notable event boundaries found to a greater extent by the viewers of the visual version include those 590 seconds in, when the character Phoebe’s face appears after a pan away from the bank lobby subplot; 750 seconds in, with a fade to black; 800 seconds in, with a hard cut; 868 seconds in, with a fade to black and obvious change in location. The audio-only group detected notable boundaries 55 seconds in, when the narrator cuts in after an edited-out theme tune; 97 seconds in, when there is the first break for sitcom laughter after a quip by the character Chandler (without any actual scene transition notable in the visual version); 550 seconds in, when there is a period of silence in the dialogue and a topic change (without any location change in the visual version); and 742 seconds in, when the audio description cuts in to describe a scene, though there is, again, no location change.
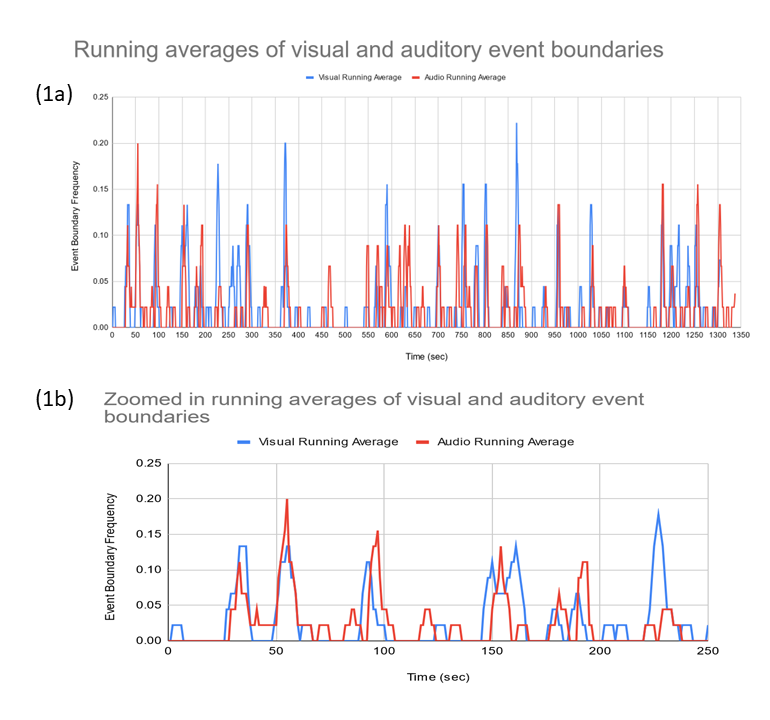
Figure 1: Displays running averages (+/- 2 seconds) of events between visual and auditory versions, from the full time course (1a) or up to 250 seconds in a version with differences more easily viewable (1b).
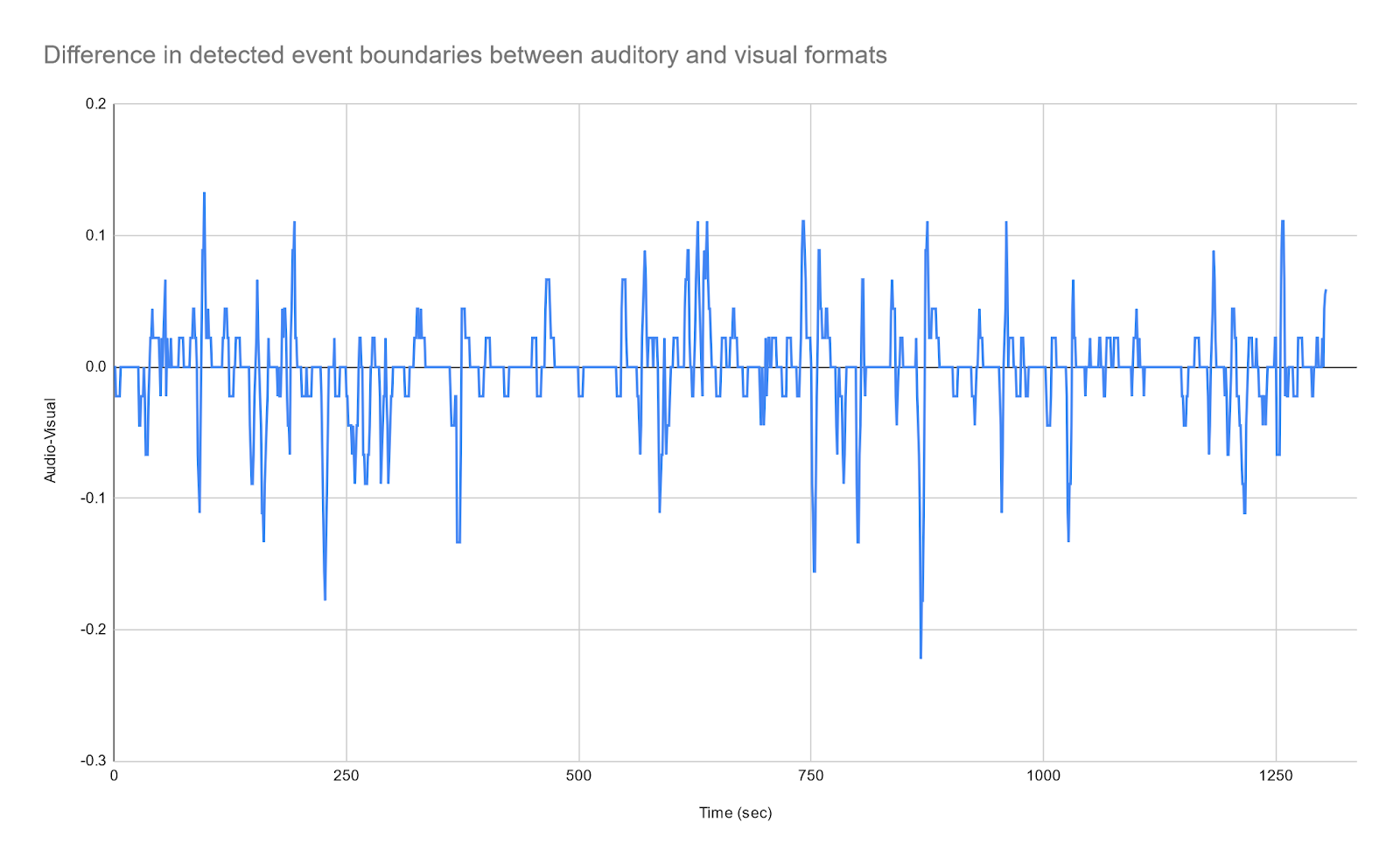
Figure 2: Difference in detected events between auditory and visual versions of the episode. Positive indicates that a greater amount of event boundaries were detected there in the auditory condition; negative indicates that a greater amount of event boundaries were detected in the visual condition.
Pearson correlation coefficients of the vectors were low, but mostly significant–this especially is the case with the initial storyboard. Between the sample storyboard of the episode I developed and the auditory running average, the coefficient is -.0146 (p-value = 0.593 > .05). Between the storyboard and the visual running average, the coefficient is 0.1358 (p-value ~ 0 < 0.05). However, it is notable that in developing the storyboard, I had access to exact timestamps of moments and the ability to pause the presentation to notate event boundaries. Participants, meanwhile, may experience some delay in pressing a button to indicate the start of a new event. For this reason, I performed several temporal shifts to examine different correlations between storyboard and the auditory and visual running averages. Shifting the storyboard to be later by 3 seconds produced the highest correlation with the visual group at 0.271 (p-value ~ 0 < 0.05); shifting the storyboard to be later by 6 seconds produced the highest correlation with the audio running averages at 0.276 (p-value ~ 0 < 0.05). Between the visual running average and the auditory running average, the coefficient is higher, at .4232.
Free Recall
The results of the t-test indicated that results were statistically insignificant (p-value 0.411 > 0.05). Figure 3 displays the difference in recollected details with results from all included participants’ average number of details recollected were 43.824 in the mixed visual/audio group and 41.167 in the constant visual/visual group. Standard errors were large–8.035 in the mixed visual/audio group and 8.594 in the constant visual/visual group. There was a high variation between participants in the number of details reported.
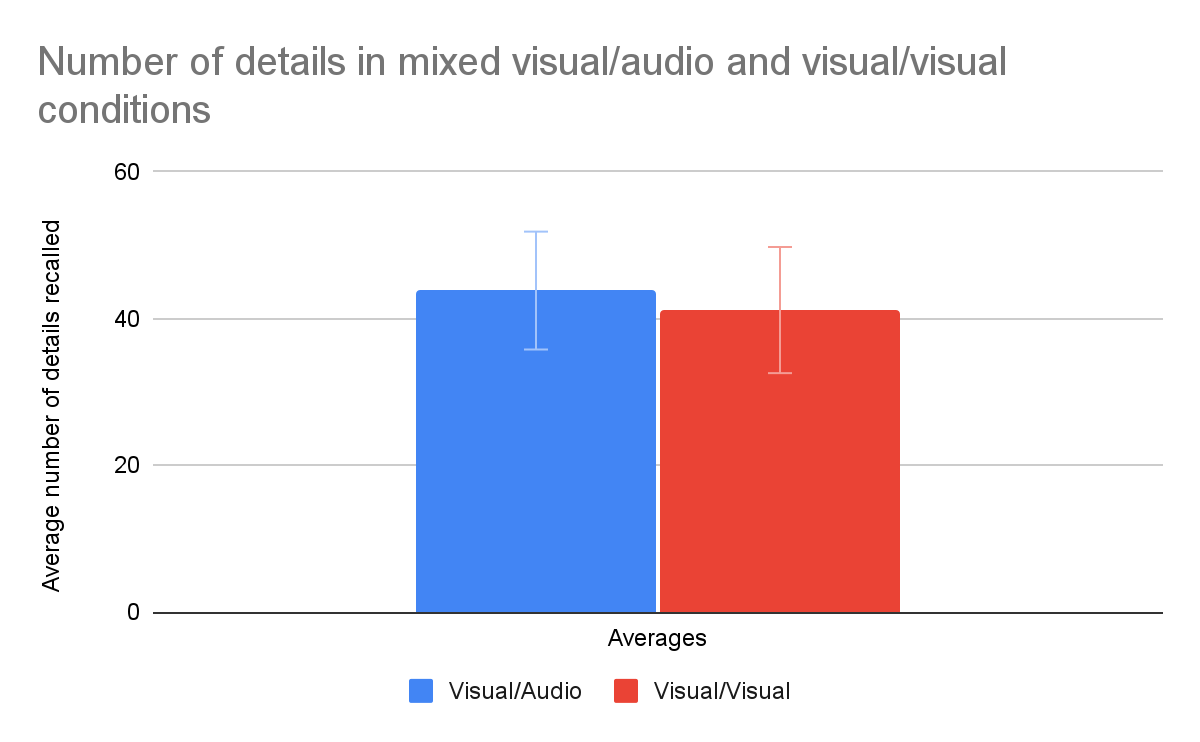
According to this data tabulation, participants who had seen Friends before displayed oddities in reported results. In the mixed-modality condition, the average number of details recollected by those who had watched the entirety of Friends was 32.375, which was unexpectedly lower than the number of details recollected by those who hadn’t viewed Friends. Additionally, standard deviation of participants who hadn’t seen Friends in the constant-modality condition was 32.590, while it was much higher at 45.632 in those who had seen Friends–both the largest and smallest degrees of engagement and reported details were recorded in this group. We decided to view results excluding participants who had seen Friends before. This left 12 participants in the constant-modality group and 9 participants in the mixed-modality group.
The average number of details recorded from participants who hadn’t watched Friends before across the mixed and constant modality groups is shown in Figure 4. Results were again insignificant (p-value 0.165 > 0.05). Average number of details recollected was 54.000 in the mixed visual/audio group and 37.417 in the constant visual/visual group. Standard errors were larger than in the former group, 13.482 in the mixed visual/audio group and 10.863 in the constant visual/visual group. There was a high variation between participants in the number of details reported.
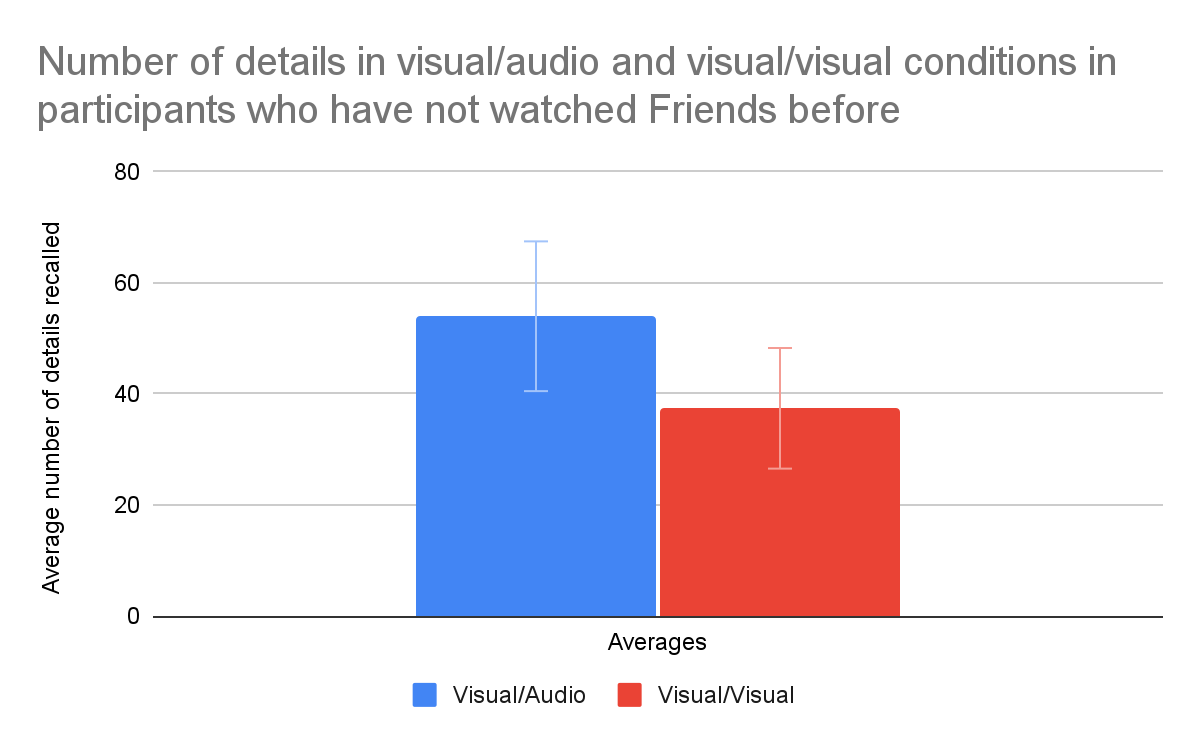
Figure 4: Displays the average number of details recalled between the mixed visual/audio and constant visual/visual groups when prior watchers of Friends were excluded.
I also attempted to find patterns between which scenes were recalled more or less often. There were three scenes the mixed modality group recalled with higher levels of detail than the constant modality group–in the first, the characters Rachel and Ross are chatting about their various weird experiences, commiserating about love and passion (the mixed-modality group remembered on average 0.551 greater details than the constant-modality group); in the second, Rachel meets a handsome Italian man, holding a cat (the mixed-modality group remembered on average 0.594 details than the constant-modality group); and in the third, Jill and Chandler become friends in the bank lobby (the mixed-modality group remembered on average 0.780 details more than the constant-modality group). These scenes all are dialogue-heavy, with relatively little movement from a particular setting. They also feature only two characters, the audio description narrator cuts in rarely, and there is also notably less sitcom laughter in these scenes. A scene wherein Joey enters the apartment with a lit menorah was remembered to a greater extent in the constant modality format than the mixed-modality format, couched between two scenes at the bank lobby (the constant-modality group remembered on average 0.386 more details than the varied-modality group). This is one scene where the five friends in the apartment subplot are moving about the apartment and talking with each other at once. On a different note, in the actual recall transcripts, all participants included some degree of integration across different narrative beats, mixing scenes that occurred in different chronological order if they contained the same character; this misordering of scenes was often mistakenly attributed by participants as the correct order of events. Participants who recalled details to higher degrees of specificity often seemed to remember the chronology of the episode better.
Discussion
In accordance with expectations for the event segmentation portion of the study, there were notable differences between the segmentation of events between the audio and visual formats. This was not a certainty; since the content of information was the same across both versions of the narrative, it was possible that event boundaries would be the same across both conditions. Events boundaries favored by the visual group over the auditory group involved hard cuts, fades to black, or abrupt appearances of a new character after a scene that had previously not involved them. Event boundaries favored by the auditory group predictably involved auditory cues like music, laughter, and silence, though these may not have been accompanied by a change in scene. By isolating modalities, we attempted to provide participants a simple way to vary encoding strategies of the same event. The resulting segmentation of events is consistent with prior understanding of event segmentation in narratives (Baldassano, 2017). Correlating the storyboard with the auditory and visual running averages was illuminating, and revealed a distinct lag favored by the auditory group compared to the visual group. This is likely due to the auditory group relying on the audio description narrator to describe scene changes, which cannot happen as quickly as visual cuts.
Results for the free recall portion of the study were mixed. These results were clearly not statistically significant, with p-values > 0.1 both when all participants were included and when participants who had previously watched Friends were excluded. Counterintuitively, the exclusion of prior Friends viewers actually increased the number of recollected details in the mixed-modality condition. This is most likely due to a decreased engagement with the study experienced by participants who had viewed Friends before in its intended format. Despite this, a preliminary pattern does emerge where the mixed-modality format reveals an increased number of details. This is in accordance with our hypothesis. In analyzing results scene by scene, the mixed-modality group improved the most in scenes that involved heavy dialogue. While these scenes did not introduce any additional cues that could only be picked up by the audio version of the episode, it is possible that improvement to memory would be most markedly enhanced as these scenes are more compatible with both auditory and visual presentations than ones involving more physical comedy.
There are many limitations to the current study, the most obvious being the limited sample sizes. In addition, there are problems that come with a lack of generalizability in using only undergraduate students, which are exacerbated by this study’s entirely online format. Using Zoom for the free recall portion of the study comes with its own set of problems, in particular, the lag that often accompanies screensharing. Another problem comes in the rather flexible detail assignment necessary by the methodology of the free recall portion of the study. With myself as the only assigner of details across the randomized transcripts, human error in this portion is an unavoidable consideration. An increased number of raters with high interrater reliability would have been ideal. In addition, it is not entirely clear what changing modality actually means in terms of encoding variability. While we have postulated that there is some evidence this might be equivalent to varying encoding strategy, as in Huff (2014), there is not much support in this line of literature. While this study seeks to introduce interesting questions regarding the relationship between encoding variability and event segmentation, by no means can it causally relate the two. In addition, though Friends is rich with differences between the auditory and visual experience, such as in the presentation of sitcom laughter and character expressions, a narrative that minimized these differences might be a more helpful grounding in ensuring that changing modality was targeting changing encoding strategy, not encoding task, as in prior studies (Smith, 2014).
Future research should attempt to mitigate these limitations. An expanded sample would have greatly assisted the results of this study. A different follow-up might examine the integration of scenes witnessed by participants and the extent to which this may help or harm memory–prior research has shown that increased integration, assisted by coherence, should assist memory in narratives, but this slightly differs from the qualitative results of our small sample (Cohn-Sheehy, 2020). Results from this study do provide a groundwork for expansion in this area of understanding of learning and memory.
References
Antony, J. W., Hartshorne, T. H., Pomeroy, K., Gureckis, T. M., Hasson, U., McDougle, S. D., & Norman, K. A. (2020). Behavioral, physiological, and neural signatures of surprise during naturalistic sports viewing. https://doi.org/10.1101/2020.03.26.008714.
Baldassano, C., Chen, J., Zadbood, A., Pillow, J. W., Hasson, U., & Norman, K. A. (2017). Discovering event structure in continuous narrative perception and memory. Neuron, 95(3). https://doi.org/10.1016/j.neuron.2017.06.041.
Cohn-Sheehy, B. I., Delarazan, A. I., Reagh, Z. M., Crivelli-Decker, J. E., Kim, K., Barnett, A. J., Zacks, J. M., & Ranganath, C. (2020). Building bridges: The hippocampus constructs narrative memories across distant events. https://doi.org/10.1101/2020.12.11.422162.
Glenberg, A. M. (1979). Component-levels theory of the effects of spacing of repetitions on recall and recognition. Memory & Cognition, 7(2), 95–112. https://doi.org/10.3758/bf03197590
Handjaras, G., Ricciardi, E., Leo, A., Lenci, A., Cecchetti, L., Cosottini, M., Marotta, G., & Pietrini, P. (2016). How concepts are encoded in the human brain: A Modality Independent, category-based cortical organization of Semantic Knowledge. NeuroImage, 135, 232–242. https://doi.org/10.1016/j.neuroimage.2016.04.063
Hintzman D.L., Stern L.D. (1978). Contextual variability and memory for frequency Journal of Experimental Psychology: Human Learning and Memory. 4, 539–549. doi: 10.1037/0278-73934.5.539
Huff, M. J., & Bodner, G. E. (2014). All varieties of encoding variability are not created equal: Separating variable processing from variable tasks. Journal of memory and language, 73, 43–58. https://doi.org/10.1016/j.jml.2014.02.004
Introduction to jsPsych. jsPsych. Retrieved June 1, 2022, from https://www.jspsych.org/7.2/
JsPsych and Jatos. JATOS. Retrieved June 1, 2022, from https://www.jatos.org/jsPsych-and-JATOS.html
Jung, Y., Larsen, B., & Walther, D. B. (2018). Modality-Independent Coding of Scene Categories in Prefrontal Cortex. The Journal of neuroscience : the official journal of the Society for Neuroscience, 38(26), 5969–5981. https://doi.org/10.1523/JNEUROSCI.0272-18.2018
Smith, S. M., & Handy, J. D. (2014). Effects of varied and constant environmental contexts on acquisition and retention. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40(6), 1582-1593. doi:http://dx.doi.org/10.1037/xlm0000019
Newtson D, Engquist G. (1976). The perceptual organization of ongoing behavior. Journal of Experimental Social Psychology. 12:436–50.
Ngrok. Retrieved June 1, 2022, from https://ngrok.com/
Young, D. R., & Bellezza, F. S. (1982). Encoding variability, memory organization, and the repetition effect. Journal of Experimental Psychology: Learning, Memory, and Cognition, 8(6), 545–559. https://doi.org/10.1037/0278-7393.8.6.545
Zacks J. M., Speer N. K., Swallow K. M., Braver T. S., & Reynolds J. R. (2007). Event perception: a mind-brain perspective. Psychological bulletin, 133(2):273–293. https://doi.org/10.1037/0033-2909.133.2.273.